This page is to discuss the next version of the log and event tracing system. The collection system is fairly robust and works well with a number of different scenarios already (syslog, windows event logs, log4j files) and can easily be written to handle network listener based events or perhaps code enhancement based eventing. Where we are currently lacking is in the long term persistent storage and analysis features.
Storage
For storage, first we need to get out of the database and into a distributed store to disk model with compression and indexing. This screams for a solution like HDFS. Others have already solved this problem using HDFS and there even exists the Chukwa project that is designed to implement a self contained solution. Chukwa is interesting because it is a solution already in use and has tackled many of the necessary topics. One downside may be the difficulty in integrating with the RHQ infrastructure to gain the most value from the cohesive management strategy tying other types of data together. E.g. the rhq agent already manages itself, upgrades itself, has reliable, secure delivery, and collects log and events data in a way that attaches it to our deep inventory system.
Analysis and Reporting
We want to be able to perform both large scale searches of the data as well as correlated analysis of specific message rates or transformation to quantitative data sets. Externalizing the data set would remove it one step from our inventory system which may make some of the analysis more difficult. (e.g. Search the logs for this "cluster" which is an RHQ inventory concept) It also would need considerable attention on the alerting integration for best results.
Requirements
-
Total audit store (all log messages stored and available) (i.e. scale to TBs of data, 1000's of monitored servers)
-
Reliable, highly-available persistence (preferably selectable CAP scenarios)
-
Distributed with geographic sensitivity so we don't have to ship full log contents between datacenters
-
Seamless installation, upgrade and management
-
Users views of reconstituted log files for a resource, cluster or arbitrary group
-
Search log files for specific messages, summaries, groupings, time-periods, etc.
-
Continue to integrate into alerting (and expand the fanciness)
-
Secondary analysis
-
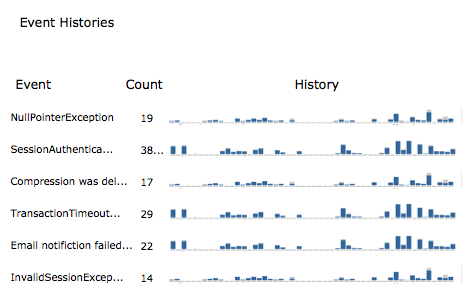
Count of types of messages graphed over time, over arbitrary sets of resources
-
Processing messages for included information (e.g. output timings, appache response codes, etc)
-
-
Do all of the above (or as much as possible) with real-time performance
Technology
Data stores on the table (so far) would probably be cassandra, voldemort and hbase... preferably with an integration with lucene. Lucandra may be a good option for us. We were also pointed at ElasticSearch and should take a look at that too.
Strategies
For computing event recurrence we can do simple grouping by entire message indexing (with at a minimum numbers removed). If we want to have more fuzzy grouping of messages that are almost the same we could use map-reduce to calculate Levenshtein distances to judge message similarity. (e.g. Removing numbers lets us group "Compression took [823ms]" and "Compression took [2423ms]") but (e.g. "User [foo] changed password" and "User [bar] changed password" would not be grouped)
Once messages are grouped, message that have interesting numeric trend data could be separated for time series plots (e.g. plotting the compression time logged above)
Cassandra
A bit of analysis on the use of cassandra for this.
Good
-
Decentralized (no central node to be a bottleneck or fail)
-
Linear horizontal scaling of writes
-
Datacenter (geographic) partitioning support with pluggable semantics so we can align its storage with our affinity model
-
Tunable consistency semantics gives flexibility in AP vs CP
-
Lucandra is *at a minimum *an example of Lucene integration with Cassandra and maybe something we can use and contribute to
-
Column family (i believe) gives us the best flexibility on log data splitting and optimized retrieval
-
map-reduce and pig integration
-
Range queries
-
Should be easy to embed in our Server VM
Bad
-
Cassandra does not yet have compression (though planned for 0.8 I believe)
-
The Thrift based API does not have streaming
Functional Designs
The following two diagrams show some ideas for displaying analyzed frequencies for important events.